블로그를 개설한지 2018년부터 현재까지 운영중이고 초라했던 개인 기록용 블로그에서 현재 일평균 약 1500 정도의 기술블로그로 성장하였다. 티스토리에서 블로그를 운영하면 통계를 분석해주는데 항상 통계로 보여지는 방문자들의 데이터의 흐름이 신기하고 궁금했다.
구글 애널리틱스 GA4와 블로그를 연동하여 데이터를 쌓고, GA4와 BigQuery와 연동을 하면 데이터를 조작할 수 있다.
평소 궁금했던 블로그 방문에 대한 데이터를 직접 분석해려고 한다.
연동하기만 하면 쌓여있는 모든 데이터들을 다 볼 수 있는지 알았는데, 그건 아니고 연동한 시점부터 데이터를 쌓기 시작하여 이후 수집 데이터들을 다룰 수 있다.
때문에 해당 포스팅에서는 12/19일-25일, 즉 1주일 간 쌓인 데이터들을 대상으로 한다.
데이터 구조
먼저 전체 조회를 통해 데이터 구조를 살펴보면

다음과 같이 데이터가 출력된다.
조금 어색한 점이 보인다. 하나의 행 안에 여러개의 데이터가 행으로 존재하고 있다. 이러한 데이터 구조를 ARRAY (배열) 구조라 하고, 같은 컬럼명이 .으로 구분되어 또 하나의 컬럼으로 나뉘는 구조를 STRUCT(구조체)라고 한다. 이는 빅쿼리에서 사용하는 NESTED 구조라고 한다.
배열 구조에서는 원하는 값에 직접적으로 접근할 수 없기 때문에 이를 위해서는 UNNEST 함수를 써서 데이터 구조를 평면화(Flatten) 해주어야 한다.
주요 컬럼
| user_pseudo_id | 사용자 고유 아이디 값 |
| event_date | 이벤트 기록 날짜 |
| event_timestamp | 이벤트 기록된 날짜 및 시간 (UTC 기준) |
| event_name | 이벤트 명 (사용된 이벤트 종류: first_visit, page_view, scroll ) |
| event_params.key | 이벤트 키 (사용된 키 종류: page_title) |
| event_params.value.string_value | 이벤트 문자열 값 (key가 page_title인 경우 문자열은 페이지 명) |
| traffic_source.source | 트래픽 유입 출처 |
| geo.country | 접속 국가 |
분석 주제
내 블로그에는 누가 다녀갔을까? 그리고 들어와서 어떤 행동을 했을까?
Q. 일별 전체 방문자수, 첫 방문자수, 재방문자수, 첫방문자의 비율
Q. 일별 시간대별 방문자 수
Q. 첫방문 이후 다음날에도 재방문한 방문자 수
Q. 가장 높은 조회수를 기록한 페이지
Q. 조회한 페이지의 스크롤 전환율 (정말 스크롤하여 글을 읽어봤는지)
Q. 방문자 유입 경로
Q. 방문자들의 거주지
Q. 일별 전체 방문자수, 첫 방문자수, 재방문자수, 첫방문자의 비율
쿼리)
SELECT event_date
, COUNT(distinct user_pseudo_id) total_visit -- 일별 전체 방문자
, COUNT(distinct IF(event_name = "first_visit",user_pseudo_id,null)) first_visit -- 첫방문자
, COUNT(distinct user_pseudo_id) - COUNT(distinct IF(event_name = "first_visit",user_pseudo_id,null)) revisit -- 재방문자
, ROUND(COUNT(distinct IF(event_name = "first_visit",user_pseudo_id,null))
/ COUNT(distinct user_pseudo_id) * 100 ,2) rate_first_visit -- 첫방문자 비율 (첫방문자/전체방문자)
FROM `devlog-371715.analytics_254657717.events_*`
WHERE PARSE_DATE('%Y%m%d', _TABLE_SUFFIX) BETWEEN DATE('2022-12-19') AND DATE('2022-12-25')
GROUP BY event_date
ORDER BY event_date
결과)
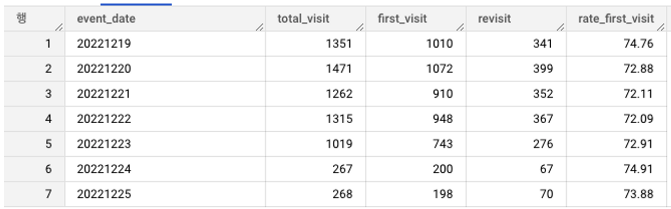
쿼리 결과 약 70% 이상이 첫 방문자이다. 블로그 특성상 개발관련 검색을 통해서 방문하는 경우가 대부분일 것이다. 블로그에서는 포스팅글이 상위 노출이 될 수록 좋다. 첫 방문자 유입이 많다는 것은 그만큼 검색 시 상위로 노출되는 글을 클릭했을 가능성이 높다고 유추해볼 수 있다.
전체 방문수를 한눈에 볼수 있도록 차트를 그려보자.
차트)
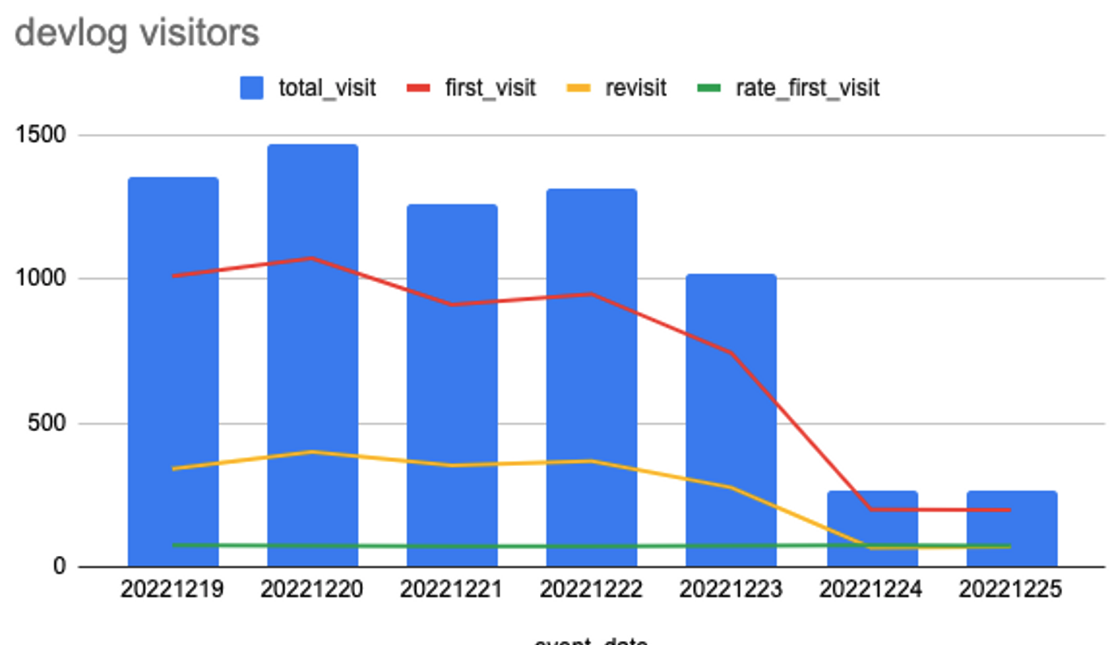
차트를 그려보니 일평균 약 1000 명 정도가 방문하는데 24-25일을 보면 갑자기 200대로 확 떨어지는 것을 확인할 수 있다. 기간을 조금 더 늘여봤더니 다음과 같은 차트가 나온다.
차트2)
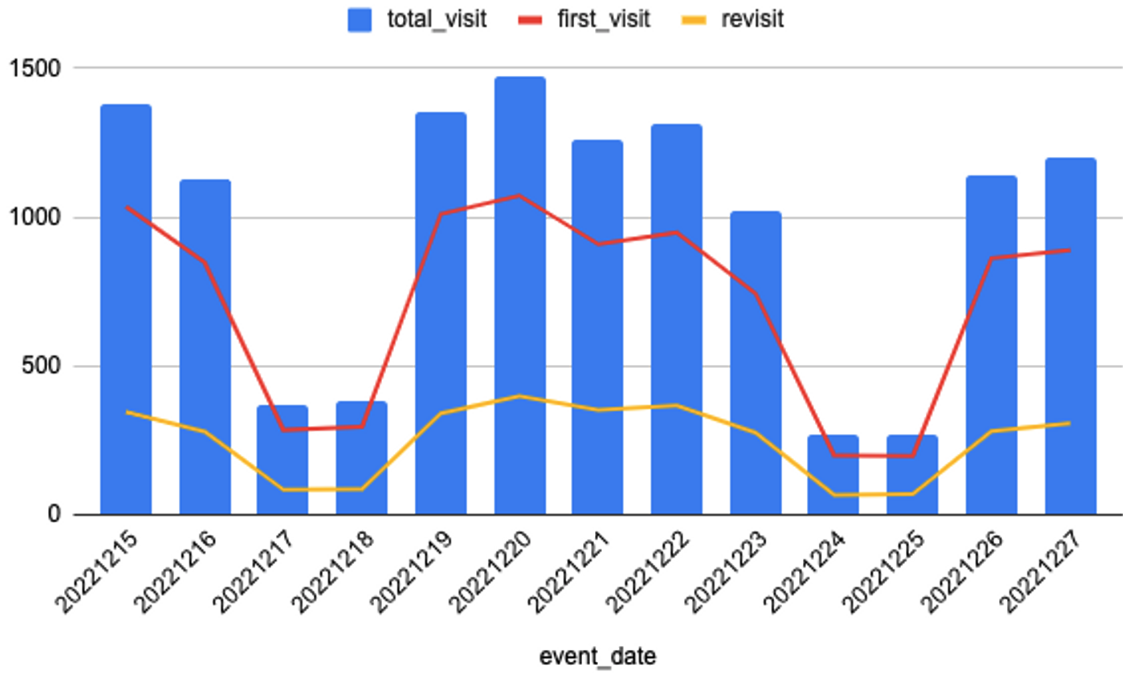
날짜를 살펴보았더니 방문수가 확 줄어드는 17-18일과 24-25 일의 기간은 토-일 즉, 주말인 것으로 보인다.
개발블로그이니 만큼 방문자들의 특성은 평일에 많이 접속한다는 것을 알 수 있다.
그렇다면 어떤 시간대에 가장 방문율이 높을까?
일별 각 시간대별로 0시~12시 까지의 방문수를 구해보자.
Q. 일별 시간대별 방문자 수
쿼리)
--시간대 별 방문자 수
SELECT
event_date
,COUNT(DISTINCT user_pseudo_id) total --하루 전체
,COUNT(DISTINCT CASE WHEN TIME(TIMESTAMP_SECONDS(CAST(CAST(event_timestamp as INT64)/1000000 as INT64)) + interval '9' hour)
BETWEEN '00:00:00' AND '00:59:59' THEN user_pseudo_id END)
AS time00
,COUNT(DISTINCT CASE WHEN TIME(TIMESTAMP_SECONDS(CAST(CAST(event_timestamp as INT64)/1000000 as INT64)) + interval '9' hour)
BETWEEN '01:00:00' AND '01:59:59' THEN user_pseudo_id END)
AS time01
,COUNT(DISTINCT CASE WHEN TIME(TIMESTAMP_SECONDS(CAST(CAST(event_timestamp as INT64)/1000000 as INT64)) + interval '9' hour)
BETWEEN '02:00:00' AND '02:59:59' THEN user_pseudo_id END)
AS time02
,COUNT(DISTINCT CASE WHEN TIME(TIMESTAMP_SECONDS(CAST(CAST(event_timestamp as INT64)/1000000 as INT64)) + interval '9' hour)
BETWEEN '03:00:00' AND '03:59:59' THEN user_pseudo_id END)
AS time03
,COUNT(DISTINCT CASE WHEN TIME(TIMESTAMP_SECONDS(CAST(CAST(event_timestamp as INT64)/1000000 as INT64)) + interval '9' hour)
BETWEEN '04:00:00' AND '04:59:59' THEN user_pseudo_id END)
AS time04
,COUNT(DISTINCT CASE WHEN TIME(TIMESTAMP_SECONDS(CAST(CAST(event_timestamp as INT64)/1000000 as INT64)) + interval '9' hour)
BETWEEN '05:00:00' AND '05:59:59' THEN user_pseudo_id END)
AS time05
,COUNT(DISTINCT CASE WHEN TIME(TIMESTAMP_SECONDS(CAST(CAST(event_timestamp as INT64)/1000000 as INT64)) + interval '9' hour)
BETWEEN '06:00:00' AND '06:59:59' THEN user_pseudo_id END)
AS time06
,COUNT(DISTINCT CASE WHEN TIME(TIMESTAMP_SECONDS(CAST(CAST(event_timestamp as INT64)/1000000 as INT64)) + interval '9' hour)
BETWEEN '07:00:00' AND '07:59:59' THEN user_pseudo_id END)
AS time07
,COUNT(DISTINCT CASE WHEN TIME(TIMESTAMP_SECONDS(CAST(CAST(event_timestamp as INT64)/1000000 as INT64)) + interval '9' hour)
BETWEEN '08:00:00' AND '08:59:59' THEN user_pseudo_id END)
AS time08
,COUNT(DISTINCT CASE WHEN TIME(TIMESTAMP_SECONDS(CAST(CAST(event_timestamp as INT64)/1000000 as INT64)) + interval '9' hour)
BETWEEN '09:00:00' AND '09:59:59' THEN user_pseudo_id END)
AS time09
,COUNT(DISTINCT CASE WHEN TIME(TIMESTAMP_SECONDS(CAST(CAST(event_timestamp as INT64)/1000000 as INT64)) + interval '9' hour)
BETWEEN '10:00:00' AND '10:59:59' THEN user_pseudo_id END)
AS time10
,COUNT(DISTINCT CASE WHEN TIME(TIMESTAMP_SECONDS(CAST(CAST(event_timestamp as INT64)/1000000 as INT64)) + interval '9' hour)
BETWEEN '11:00:00' AND '11:59:59' THEN user_pseudo_id END)
AS time11
,COUNT(DISTINCT CASE WHEN TIME(TIMESTAMP_SECONDS(CAST(CAST(event_timestamp as INT64)/1000000 as INT64)) + interval '9' hour)
BETWEEN '12:00:00' AND '12:59:59' THEN user_pseudo_id END)
AS time12
,COUNT(DISTINCT CASE WHEN TIME(TIMESTAMP_SECONDS(CAST(CAST(event_timestamp as INT64)/1000000 as INT64)) + interval '9' hour)
BETWEEN '13:00:00' AND '13:59:59' THEN user_pseudo_id END)
AS time13
,COUNT(DISTINCT CASE WHEN TIME(TIMESTAMP_SECONDS(CAST(CAST(event_timestamp as INT64)/1000000 as INT64)) + interval '9' hour)
BETWEEN '14:00:00' AND '14:59:59' THEN user_pseudo_id END)
AS time14
,COUNT(DISTINCT CASE WHEN TIME(TIMESTAMP_SECONDS(CAST(CAST(event_timestamp as INT64)/1000000 as INT64)) + interval '9' hour)
BETWEEN '15:00:00' AND '15:59:59' THEN user_pseudo_id END)
AS time15
,COUNT(DISTINCT CASE WHEN TIME(TIMESTAMP_SECONDS(CAST(CAST(event_timestamp as INT64)/1000000 as INT64)) + interval '9' hour)
BETWEEN '16:00:00' AND '16:59:59' THEN user_pseudo_id END)
AS time16
,COUNT(DISTINCT CASE WHEN TIME(TIMESTAMP_SECONDS(CAST(CAST(event_timestamp as INT64)/1000000 as INT64)) + interval '9' hour)
BETWEEN '17:00:00' AND '17:59:59' THEN user_pseudo_id END)
AS time17
,COUNT(DISTINCT CASE WHEN TIME(TIMESTAMP_SECONDS(CAST(CAST(event_timestamp as INT64)/1000000 as INT64)) + interval '9' hour)
BETWEEN '18:00:00' AND '18:59:59' THEN user_pseudo_id END)
AS time18
,COUNT(DISTINCT CASE WHEN TIME(TIMESTAMP_SECONDS(CAST(CAST(event_timestamp as INT64)/1000000 as INT64)) + interval '9' hour)
BETWEEN '19:00:00' AND '19:59:59' THEN user_pseudo_id END)
AS time19
,COUNT(DISTINCT CASE WHEN TIME(TIMESTAMP_SECONDS(CAST(CAST(event_timestamp as INT64)/1000000 as INT64)) + interval '9' hour)
BETWEEN '20:00:00' AND '20:59:59' THEN user_pseudo_id END)
AS time20
,COUNT(DISTINCT CASE WHEN TIME(TIMESTAMP_SECONDS(CAST(CAST(event_timestamp as INT64)/1000000 as INT64)) + interval '9' hour)
BETWEEN '21:00:00' AND '21:59:59' THEN user_pseudo_id END)
AS time21
,COUNT(DISTINCT CASE WHEN TIME(TIMESTAMP_SECONDS(CAST(CAST(event_timestamp as INT64)/1000000 as INT64)) + interval '9' hour)
BETWEEN '22:00:00' AND '22:59:59' THEN user_pseudo_id END)
AS time22
,COUNT(DISTINCT CASE WHEN TIME(TIMESTAMP_SECONDS(CAST(CAST(event_timestamp as INT64)/1000000 as INT64)) + interval '9' hour)
BETWEEN '23:00:00' AND '23:59:59' THEN user_pseudo_id END)
AS time23
FROM `devlog-371715.analytics_254657717.events_*`
WHERE PARSE_DATE('%Y%m%d', _TABLE_SUFFIX) BETWEEN DATE('2022-12-19') AND DATE('2022-12-25')
GROUP BY event_date
ORDER BY event_date결과)

일시로 그룹화하여 CASE 문을 써서 각 시간대별 방문기록을 뽑아보았다.
차트)
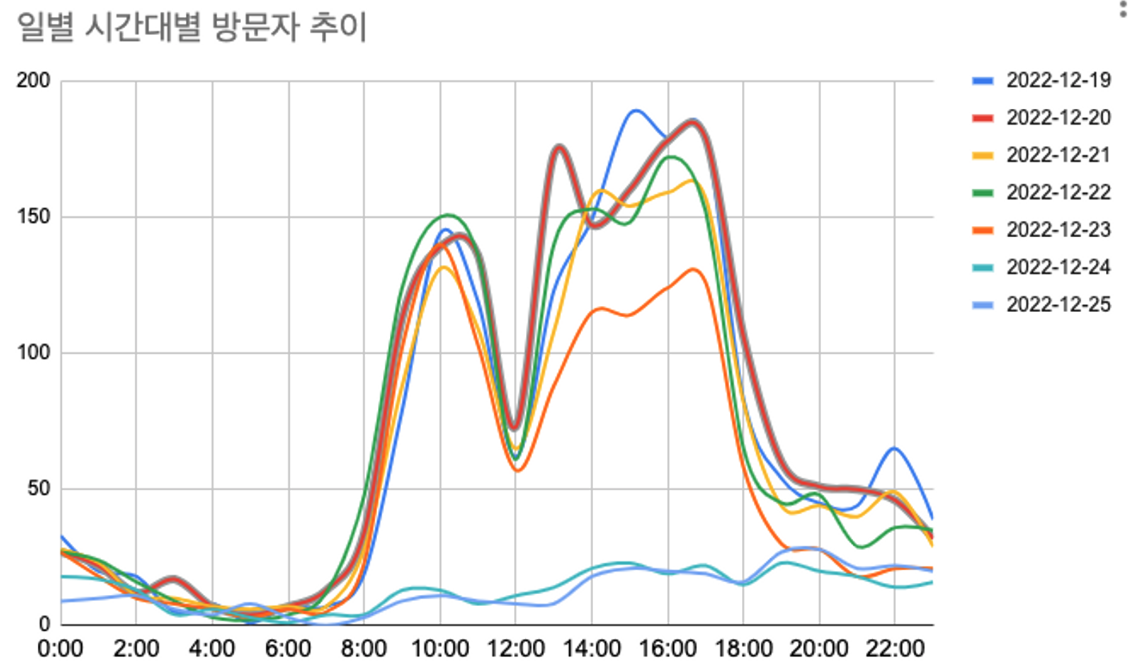
차트를 그려보면, 주말인 24-25일을 제외한 평일에는 9시-10시, 그리고 점심시간 이후인 1시-6시 사이에 가장 높은 추이를 보이고 있다.
시간상으로 유추해 보았을 때, 평균적인 근무시간과 일치하는 것을 알 수 있었다.
개발블로그라는 블로그의 특성을 고려하면 개발자로 일하는 직장인들이 업무시간에 검색을 하며 방문한 것으로 추정된다. 즉, 이 블로그의 주요 이용자들은 개발 업무 중인 직장인 등으로 추측해 볼 수 있겠다.
Q. 첫방문 이후 방문 리텐션
쿼리)
-- 각 유저의 첫방문일자
WITH first_visit AS (
SELECT distinct user_pseudo_id, event_date
FROM `devlog-371715.analytics_254657717.events_*`
WHERE PARSE_DATE('%Y%m%d', _TABLE_SUFFIX) BETWEEN DATE('2022-12-19') AND DATE('2022-12-25')
AND event_name= 'first_visit'
ORDER BY event_date
)
-- 첫방문 이후 방문자.
SELECT f.event_date
,COUNT(distinct a.user_pseudo_id) day0
,COUNT(distinct CASE WHEN PARSE_DATE('%Y%m%d', a.event_date)= DATE_ADD(PARSE_DATE('%Y%m%d', f.event_date), INTERVAL 1 DAY)
THEN a.user_pseudo_id END ) day1 -- +1일
,COUNT(distinct CASE WHEN PARSE_DATE('%Y%m%d', a.event_date)= DATE_ADD(PARSE_DATE('%Y%m%d', f.event_date), INTERVAL 2 DAY)
THEN a.user_pseudo_id END ) day2 -- +2일
,COUNT(distinct CASE WHEN PARSE_DATE('%Y%m%d', a.event_date)= DATE_ADD(PARSE_DATE('%Y%m%d', f.event_date), INTERVAL 3 DAY)
THEN a.user_pseudo_id END ) day3 -- +3일
,COUNT(distinct CASE WHEN PARSE_DATE('%Y%m%d', a.event_date)= DATE_ADD(PARSE_DATE('%Y%m%d', f.event_date), INTERVAL 4 DAY)
THEN a.user_pseudo_id END ) day4 -- +4일
,COUNT(distinct CASE WHEN PARSE_DATE('%Y%m%d', a.event_date)= DATE_ADD(PARSE_DATE('%Y%m%d', f.event_date), INTERVAL 5 DAY)
THEN a.user_pseudo_id END ) day5 -- +5일
,COUNT(distinct CASE WHEN PARSE_DATE('%Y%m%d', a.event_date)= DATE_ADD(PARSE_DATE('%Y%m%d', f.event_date), INTERVAL 6 DAY)
THEN a.user_pseudo_id END ) day6 -- +6일
FROM `devlog-371715.analytics_254657717.events_*` a
JOIN first_visit f
ON a.user_pseudo_id = f.user_pseudo_id
WHERE PARSE_DATE('%Y%m%d', _TABLE_SUFFIX) BETWEEN DATE('2022-12-19') AND DATE('2022-12-25')
GROUP BY f.event_date
ORDER BY f.event_date결과)
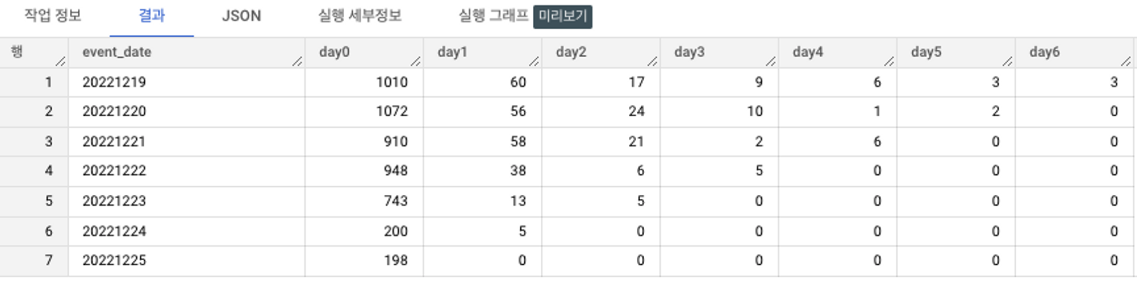
리텐션 비율)
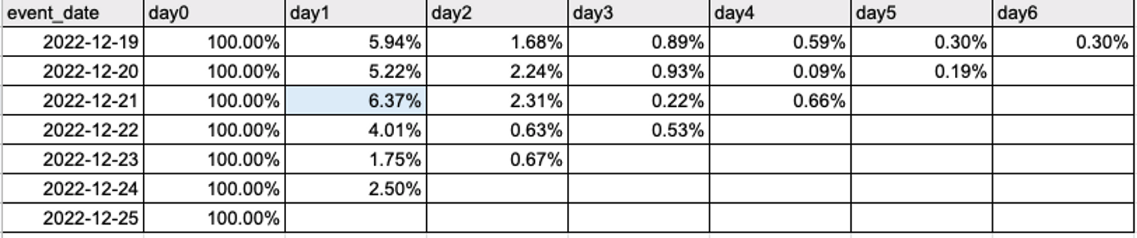
차트)
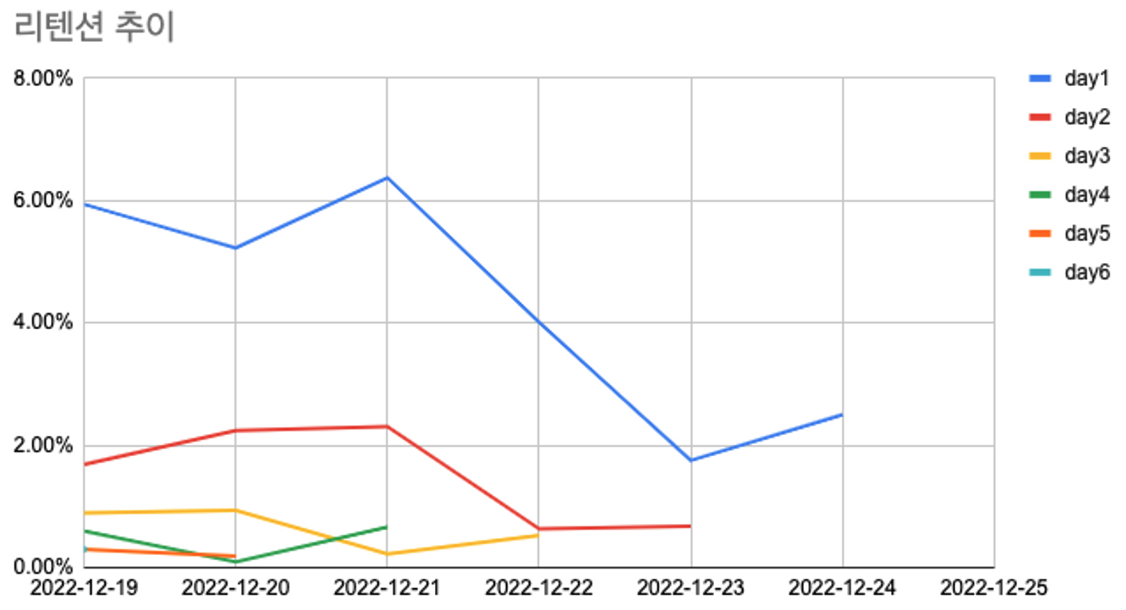
- 코호트별 리텐션이 전반적으로 하락 중.
- 바로 다음날인 day1 리텐션의 비율이 상대적으로 높다.
- 2022-12-21 첫 방문자들의 리텐션 높음
전반적으로 하락중인 리텐션이 21일에 왜 올랐을까?
해당 날짜의 블로그의 기록을 확인해보았더니, 새 글을 발행한 날이다.
새로운 글의 발행에 따라 리텐션이 상승함을 예측할 수 있다.(??)
*리텐션의 경우 일주일 데이터로 꾸역꾸역 배운걸 적용해보긴 했는데 전체 기간도 부족하고
일주일이다보니 하루기준으로 설정할수 밖에 없었던 부분으로 유의미한 결과라고 보기 힘듦..
추후 기간을 늘여 다시 시도해보자..
Q.방문자 유입 경로
쿼리)
SELECT traffic_source.source
, COUNT(distinct user_pseudo_id) cnt
FROM `devlog-371715.analytics_254657717.events_*`
WHERE PARSE_DATE('%Y%m%d', _TABLE_SUFFIX) BETWEEN DATE('2022-12-19') AND DATE('2022-12-25')
GROUP BY traffic_source.source,traffic_source.medium
ORDER BY cnt desc ;결과)
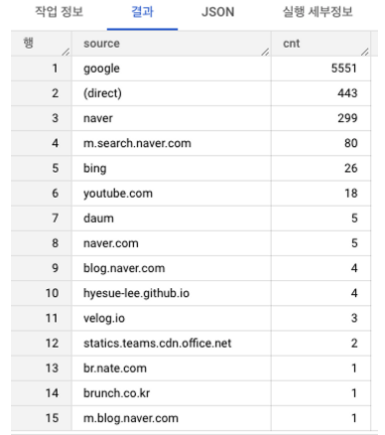
차트)
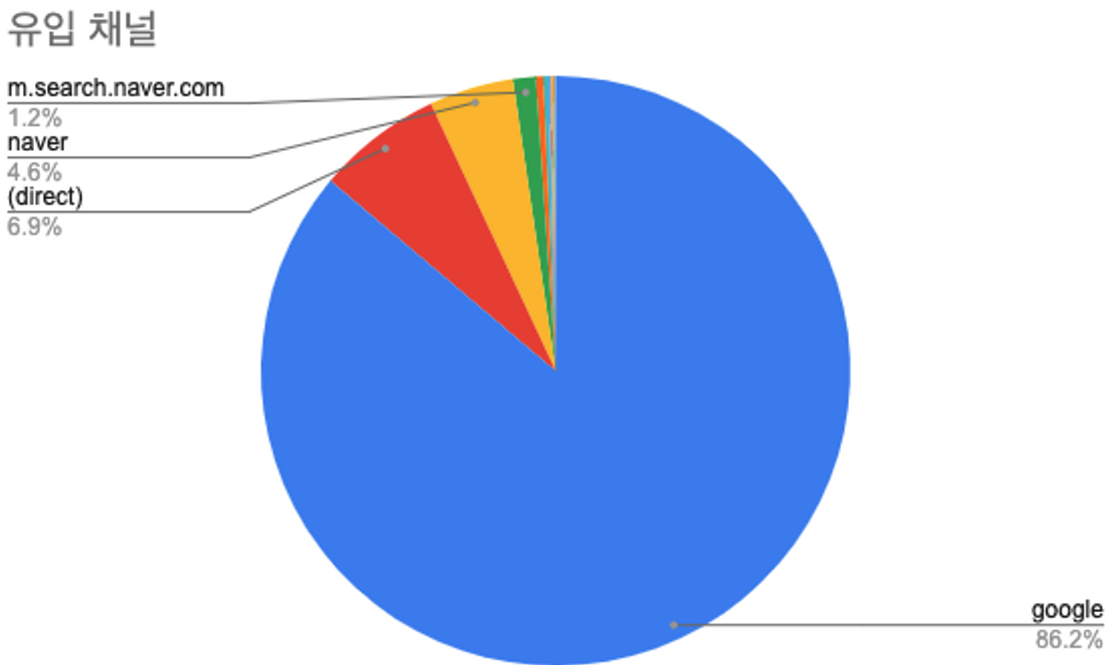
결과는 구글에서 유입되는 트래픽이 86.2%로 압도적으로 많은 것을 알 수 있다.
2순위인 (direct)는 직접 해당 url에 접속했다는 의미인데, 대부분 검색이나 유입을 통해서 들어올것이라 예상했지만 다이렉트 블로그 방문자도 존재한다. 거의 없던 구독자수가 46명으로 늘었는데 이러한 구독자들의 유입이 아닐까 예상한다.
이 외 유입채널 중, 실제 내가 활동을 하고 있고 링크를 걸어놓은 채널은 youtube, github.io, brunch 가 있고, 그 외 채널은 나와 전혀 관련이 없는 채널이다. 하지만 분석 결과, 유입에 있어서 다른 채널 활동이 유의미하게 작용하고 있지는 않다.
블로그의 평균 방문자수를 높이기 위해서는 기존 구글 검색 유입률을 높이거나 꾸준히 방문하는 구독자수를 높이는 것이 효율적일 것이다.
이번에는 조회수를 기준으로 어떤 페이지가 가장 유입이 많은지 분석해보자.
가장 높은 조회수를 기록한 페이지 구하기.
- event_name이 page_view 인 것들의 page_title 구하기
먼저 페이지명 데이터가 저장되어있는 event_params의 값을 살펴보면
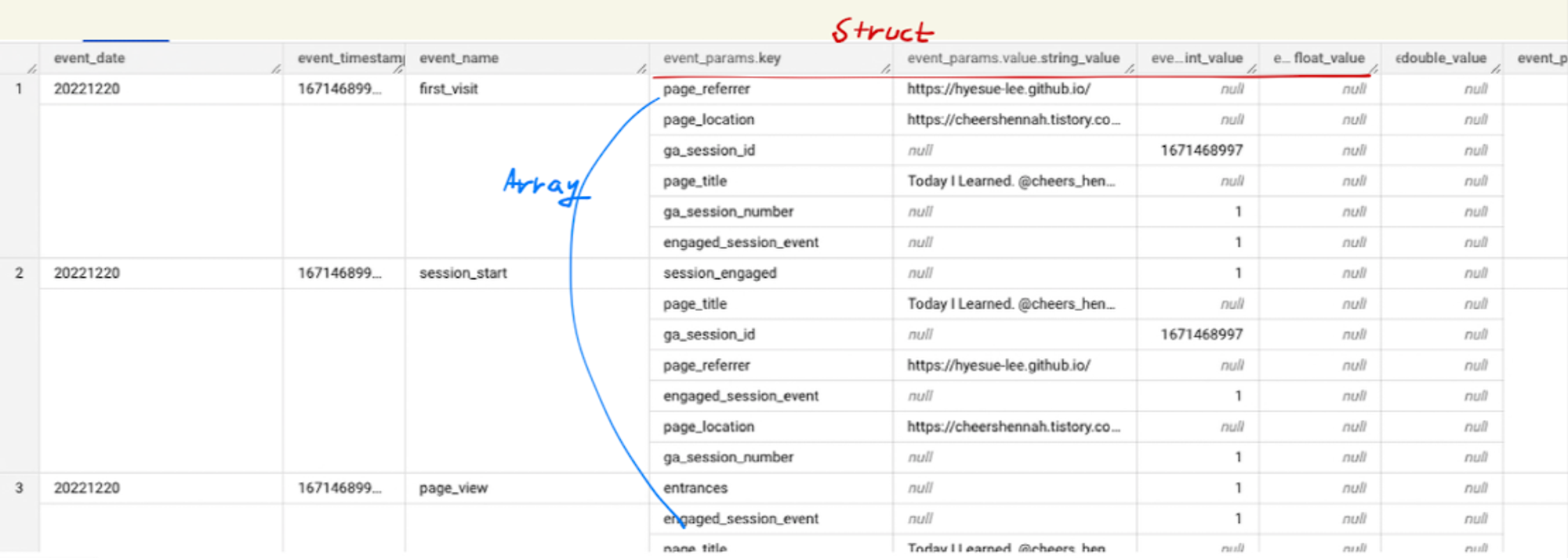
앞서 설명했던 배열ARRAY, 구조체 STRUCT 문법이 사용된 데이터 구조이다.
배열 구조에서는 원하는 값에 단일적으로 접근할수 없기 때문에 UNNEST 함수를 써서 데이터 구조를 평면화(Flatten) 해주어야 한다.
쿼리)
SELECT event_params.key,event_params.value
FROM `devlog-371715.analytics_254657717.events_20221220`
,UNNEST(event_params) AS event_params -- 배열구조 평면화
WHERE key = "page_title"결과)
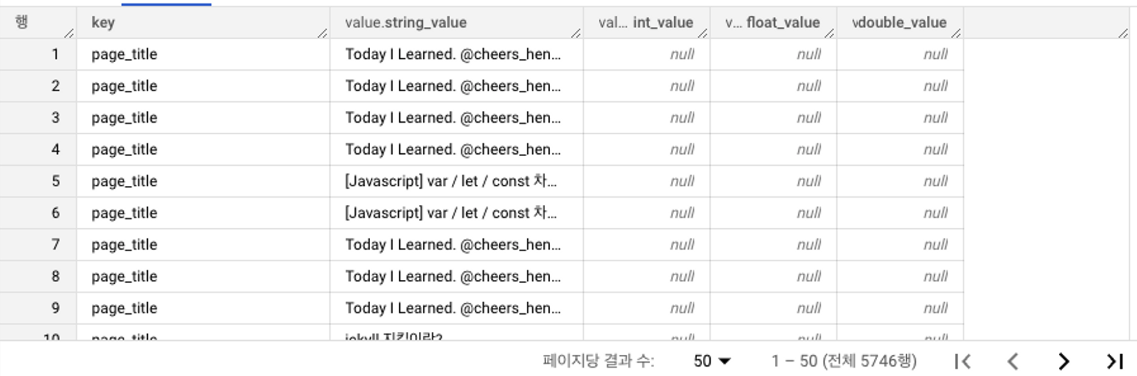
위와같이 UNNEST 함수를 사용해 배열이 풀어진 구조로 출력할 수 있다.
이제 본론으로 돌아와서 이 UNNEST함수를 하용하여 조건에 맞게 각각의 페이지들을 COUNT하여 조회수를 구해보자.
step1. 방문기록 중 event_name이 page_view이고, event_params.key가 page_title인 값을 구한다.
쿼리)
SELECT user_pseudo_id
,TIMESTAMP_SECONDS(CAST(CAST(event_timestamp as INT64)/1000000 as INT64)) + interval '9' hour as kst_date
,event_name
,event_params.key
,event_params.value.string_value
FROM `devlog-371715.analytics_254657717.events_*`
,UNNEST(event_params) AS event_params
WHERE PARSE_DATE('%Y%m%d', _TABLE_SUFFIX) BETWEEN DATE('2022-12-19') AND DATE('2022-12-25')
AND event_name="page_view"
AND key = "page_title"결과)
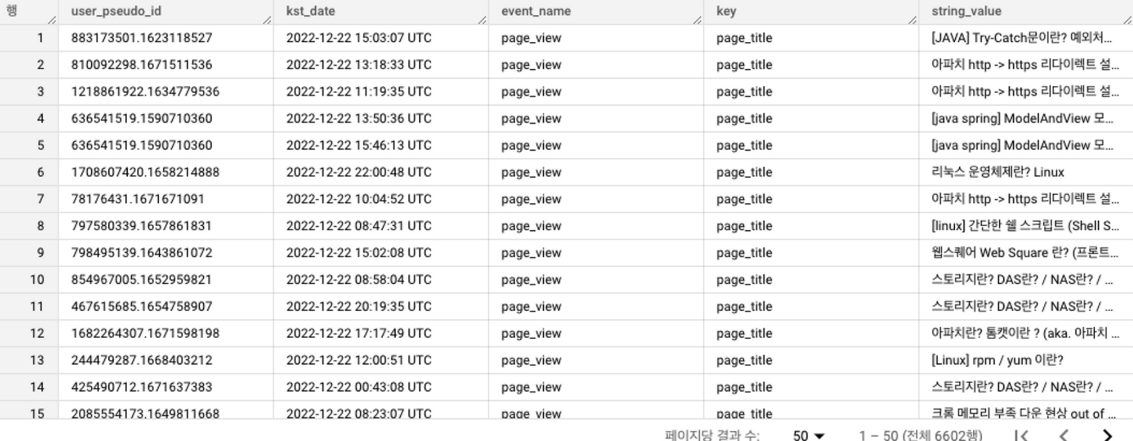
위와같이 UNNEST 함수를 사용해 배열이 풀어진 구조로 출력할 수 있다.
이제 본론으로 돌아와서 이 UNNEST함수를 하용하여 조건에 맞게 각각의 페이지들을 COUNT하여 조회수를 구해보자
step2. 방문기록 중 event_name이 page_view이고, event_params.key가 page_title인 값을 구한다.
쿼리)
SELECT user_pseudo_id
,TIMESTAMP_SECONDS(CAST(CAST(event_timestamp as INT64)/1000000 as INT64)) + interval '9' hour as kst_date
,event_name
,event_params.key
,event_params.value.string_value
FROM `devlog-371715.analytics_254657717.events_*`
,UNNEST(event_params) AS event_params
WHERE PARSE_DATE('%Y%m%d', _TABLE_SUFFIX) BETWEEN DATE('2022-12-19') AND DATE('2022-12-25')
AND event_name="page_view"
AND key = "page_title"step3. event_param.value.string_value 를 그룹화시켜 중복제거한 user_pseudo_id를 COUNT 하여 조회수를 구하고 높은순 대로 랭크를 구한다. (조회수 100 이하는 제외한다.)
결과)
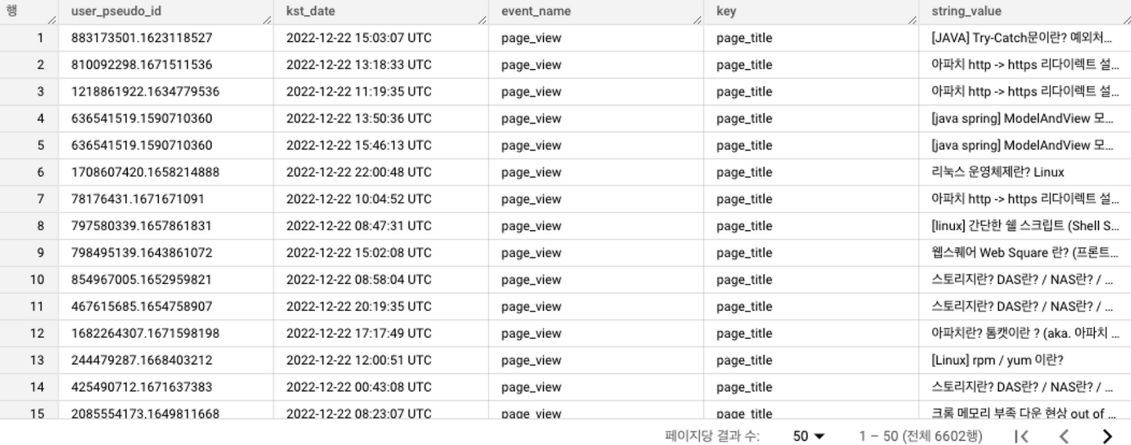
“[Spring] @RequestBody / @ResponseBody 어노테이션 이란?” 포스팅 페이지가 총 701번으로
가장 높은 조회수를 기록하고 있음을 알 수 있다.
하지만 조회수는 클릭만 해도 카운트되므로, 진짜 글을 읽어봤을까? 하는 의문이 든다.
이번에는 페이지뷰를 한 방문객 중 페이지 뷰 이후 스크롤을 했는지 전환율을 알아보자.
Q. page_view > scroll 한 수, 전환율 구하기
step1. 먼저 앞서 구한 page_view를 한 유저, 시간, 페이지네임과 시간 비교를 위해 scroll한 유저, 시간, 페이지네임을 각각 구한다.
쿼리)
SELECT user_pseudo_id
,TIMESTAMP_SECONDS(CAST(CAST(event_timestamp as INT64)/1000000 as INT64)) + interval '9' hour as kst_date
,event_name
,event_params.key
,event_params.value.string_value
FROM `devlog-371715.analytics_254657717.events_*`
,UNNEST(event_params) AS event_params
WHERE PARSE_DATE('%Y%m%d', _TABLE_SUFFIX) BETWEEN DATE('2022-12-19') AND DATE('2022-12-25')
AND event_name ="scroll" -- 스크롤
AND key = "page_title"step2. 각 구한 페이지뷰 정보와 스크롤 정보를 WITH 를 사용하여 임시테이블로 만들어 조인을 활용하여 전환율을 구한다.
쿼리)
-- 전환율
WITH pageview AS( -- 페이지 뷰
SELECT user_pseudo_id
,TIMESTAMP_SECONDS(CAST(CAST(event_timestamp as INT64)/1000000 as INT64)) + interval '9' hour as kst_date
,event_name
,event_params.key
,event_params.value.string_value
FROM `devlog-371715.analytics_254657717.events_*`
,UNNEST(event_params) AS event_params
WHERE PARSE_DATE('%Y%m%d', _TABLE_SUFFIX) BETWEEN DATE('2022-12-19') AND DATE('2022-12-25')
AND event_name ="page_view"
AND key = "page_title"
), scroll AS ( -- 스크롤
SELECT user_pseudo_id
,TIMESTAMP_SECONDS(CAST(CAST(event_timestamp as INT64)/1000000 as INT64)) + interval '9' hour as kst_date
,event_name
,event_params.key
,event_params.value.string_value
FROM `devlog-371715.analytics_254657717.events_*`
,UNNEST(event_params) AS event_params
WHERE PARSE_DATE('%Y%m%d', _TABLE_SUFFIX) BETWEEN DATE('2022-12-19') AND DATE('2022-12-25')
AND event_name ="scroll"
AND key = "page_title"
)
-- 페이지뷰 다음 스크롤까지 한 유저 : 페이지뷰 시간 <= 스크롤 시간
SELECT COUNT(distinct p.user_pseudo_id) pageview
,COUNT(distinct s.user_pseudo_id) scroll_after_pageview
,ROUND(COUNT(distinct s.user_pseudo_id)/COUNT(distinct p.user_pseudo_id)*100,2) rate
FROM pageview p
LEFT JOIN scroll s
ON p.user_pseudo_id = s.user_pseudo_id
AND p.string_value = s.string_value
AND p.kst_date <= s.kst_date
WHERE p.string_value = '[Spring] @RequestBody / @ResponseBody 어노테이션 이란?'결과)

해당 글의 전환율을 구했더니 겨우 23% 밖에 되지 않는다.
생각보다 조회수에 비해 실제로 스크롤까지 한 유저가 저조하다
그렇다면 페이지 뷰 > 스크롤 까지 한 글을 기준으로 전체 조회수를 뽑아보자.
쿼리)
SELECT
s.string_value page_title
,COUNT(distinct s.user_pseudo_id) scroll_after_pageview
FROM pageview p
LEFT JOIN scroll s
ON p.user_pseudo_id = s.user_pseudo_id
AND p.string_value = s.string_value
AND p.kst_date <= s.kst_date
GROUP BY s.string_value
ORDER BY scroll_after_pv desc결과)

1,2순위는 같지만 이후 순위에서는 순위가 바뀐 글들이 보인다.
즉, 페이지뷰가 높더라도 스크롤 전환수는 저조하고, 페이지뷰가 낮더라도 스크롤 전환수가 높은 글도 존재한다.
이 경우 후자의 경우가 좀 더 가치있는 글이라고 판단 해 볼 수 있다.
순위가 높은 포스팅 글의 내용을 살펴보니, 단순히 코드보다 코드에 대한 설명에 대해 기술해 놓은 글들이 많다. 설명이 친절한 글을 사람들은 스크롤하여 읽어본다고 추측된다.
다음은 방문한 나라들을 한번 살펴보자
Q. 방문 나라 및 순위
쿼리)
SELECT geo.country
,COUNT(distinct user_pseudo_id) as cnt
,DENSE_RANK() OVER(ORDER BY COUNT(distinct user_pseudo_id) desc) ranking
FROM `devlog-371715.analytics_254657717.events_*`
WHERE PARSE_DATE('%Y%m%d', _TABLE_SUFFIX) BETWEEN DATE('2022-12-19') AND DATE('2022-12-25')
GROUP BY country
ORDER BY cnt desc결과)
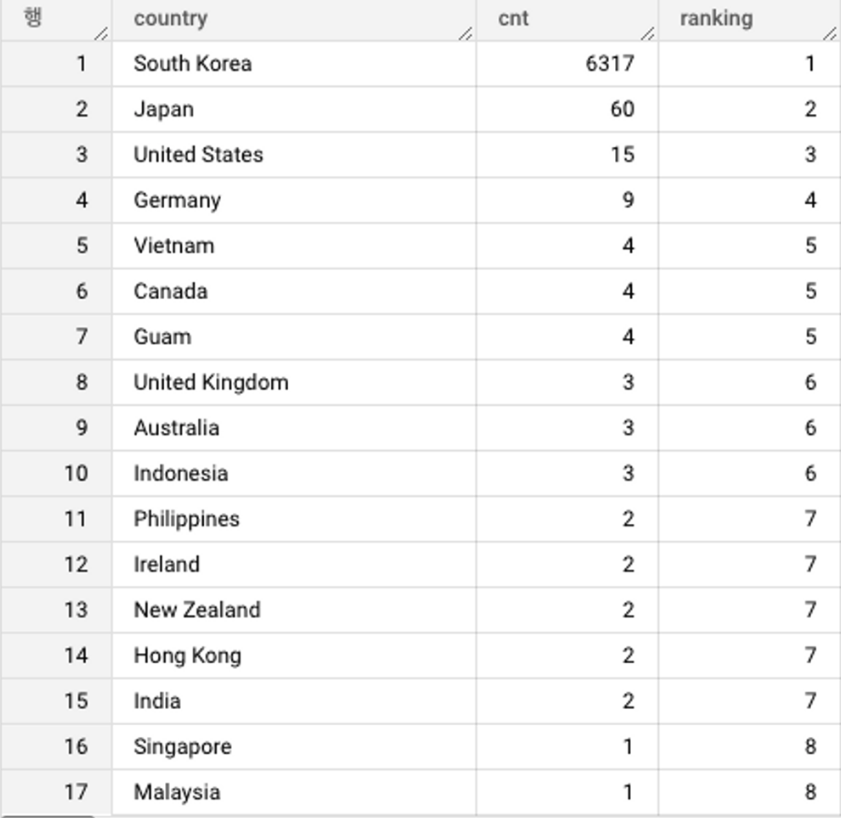
다음과 같은 결과를 얻었다. 내 블로그는 모두 한글로 쓰여지기에 해외 방문 트래픽이 항상 궁금했다.
당연히 우리나라가 압도적으로 높지만 해외에서는 생각보다 다양한 나라에서 방문기록이 남아있다.
그렇다면 이들은 어떤 글을 읽었을까?
Q. 한국을 제외한 트래픽 중 나라별 페이지뷰 수
쿼리)
WITH hits_foreign AS (
SELECT user_pseudo_id
,TIMESTAMP_SECONDS(CAST(CAST(event_timestamp as INT64)/1000000 as INT64)) + interval '9' hour as kst_date
,event_name
,event_params.key
,event_params.value.string_value
,geo.country
FROM `devlog-371715.analytics_254657717.events_*`
,UNNEST(event_params) AS event_params
WHERE PARSE_DATE('%Y%m%d', _TABLE_SUFFIX) BETWEEN DATE('2022-12-19') AND DATE('2022-12-25')
AND event_name ="page_view"
AND key = "page_title"
AND geo.country != 'South Korea'
)
-- hits from foreign
SELECT string_value page_title
,COUNT(distinct user_pseudo_id) hits
FROM hits_foreign
GROUP BY string_value
ORDER BY hits desc결과)
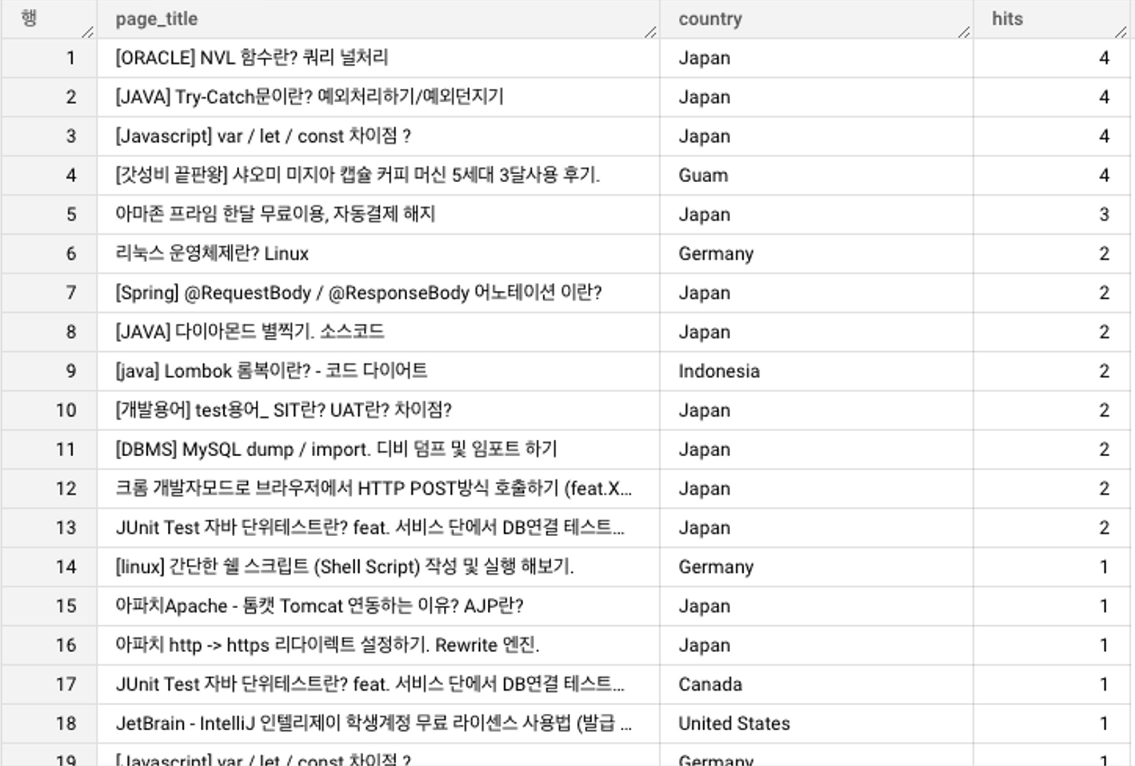
재미있는 결과가 나왔다. 예상컨대, 블로그 글에서 소스코드를 제외한 모든 설명은 한글로 작성되기 때문에 코드가 많이 들어간 포스팅이 아닐까? 예상했는데, 그렇지만도 않다. 심지어 코딩과 전혀 관계가 없는 글도 보인다.
거의 모든 글이 개발관련 포스팅이지만 종종 다른 카테고리에서 상품 후기 등을 포스팅하기도 했는데, 해당글이 보이기도 하고 소스코드의 비중이 적은 개발관련 포스팅도 있는것으로 보아 외국인이 유입되었기보다는, 해외에 거주하고 있는 한국인들의 유입에 더 가깝지 않을까 추측 된다.
KPT 회고
Keep
- 평소 개인 블로그의 시각화로 제공되는 통계 데이터에 대한 궁금증을 항상 가지고 있었는데 이번 기회로 Google Analytics와 BigQuery를 연동하여 직접 데이터에 접근해볼 수 있어서 많은 궁금증이 해소 되었다.
- 이미 정제된 데이터로 배운 내용을 실제 raw 데이터에 적용하여 데이터를 정제해보는 과정이 흥미로웠다.
Problem
- 빅쿼리 연동 시 전체 데이터를 볼 수 있는것이 아니라, 연동 시점부터 데이터를 수집하기 때문에 단기간의 주간 데이터 진행할 수 밖에 없어 리텐션 등에서 유의미한 결과를 도출하지 못함
- 분석 대상이 단순 개인 블로그였기 때문에 코호트를 나누는 기준이 방문에 한계되고, 단순 궁금증으로 시작하다보니 목표가 명확하기 못함.
- 제안 및 액션 아이디어 도출이 어려웠음.
Try
- 목표가 명확한 데이터 분석을 기반으로 액션까지 제시해보도록 하자.
- 액션을 적용해본 후, 전후 비교 분석을 해보자
- 충분한 데이터를 수집한 다음 2차 분석을 해보자
'Data Analytics' 카테고리의 다른 글
| 시계열 데이터 분석이란? Time Series Analysis (0) | 2023.02.21 |
|---|---|
| AARRR 이란? 단계별로 알아보기. +퍼널분석, 코호트, 리텐션 (0) | 2023.02.09 |
| GA(Google Analytics)란? (0) | 2023.01.03 |
| Cohort 코호트 분석이란? (0) | 2022.12.16 |
| 윈도우 함수_ 순위함수 RANK, DENSE_RANK, ROW_NUMBER (0) | 2022.12.16 |