Data Sharding.
분산 컴퓨팀 환경 내 여러 노드 또는 서버에 대규모 데이터 세트를 수평으로 분할하고 배포하기 위해 빅데이터 시스템에 사용되는 주요기술.
Dataset을 샤드(Shard)라고 하는 더 작고 관리하기 쉬운 조각으로 나누어 데이터 관리, 확장성 및 성능 향상을 목표로 함.
데이터 샤딩을 사용하는 이유?
데이터 배포 및 병렬처리 향상.
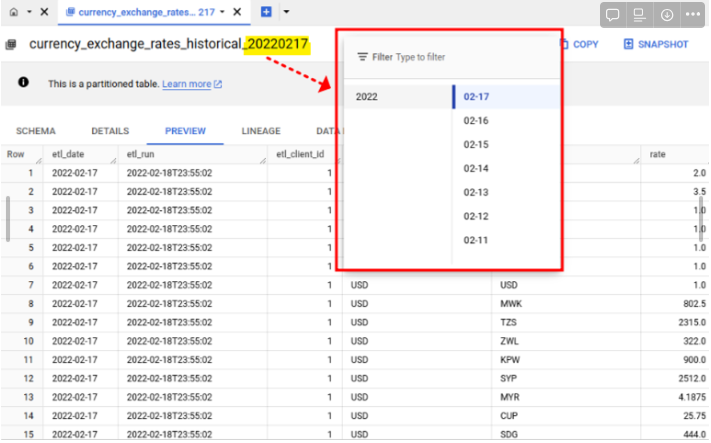
빅쿼리는 위와같이 일별로 분할된 테이블을 생성한다.
이를 테이블 샤딩이라고(Table Sharding) 하며 이러한 방식은 쿼리 속도를 높이고, 데이터 중복을 방지하며, 테이블 그룹관리를 위한 유연한 옵션을 제공함.
테이블 샤딩 장점
샤딩은 쿼리의 각 날짜에 자체 테이블이 존재하므로 하루의 데이터가 중복되는 것을 방지함.
세트의 모든 테이블은 동일한 테이블 구조를 가질 필요는 없다. 원래 데이터 구조를 유지하면서 테이블 그룹에서 열을 쉽게 추가 및 제거할 수 있다.
Looker Studio는 기본적으로 빅쿼리의 샤딩된 테이블에 연결된다. 빅쿼리의 비용 절감 및 쿼리 속도를 향상시킨다.
샤딩된 테이블 집합은 데이터 세트에서 다음과 같다.
TEST_TABLE_(365)
갹 샤딩된 테이블에는 365개의 서로 다른 테이블이 포함되어 있으며 각 테이블에는 하루동안의 데이터가 존재한다.
개별적으로 나열하면 다음과 같이 동일한 prefix의 테이블명 뒤에 _YYYYMMDD 의 suffix가 붙는형식이다.
TEST_TABLE_20240101
TEST_TABLE_20240102
TEST_TABLE_20240103
…
샤딩(Sharding) 테이블과 파티셔닝(Partitioning) 테이블.
빅쿼리의 파이셔닝 테이블은 샤딩 테이블과 비슷한 목표를 달성한다.
이는 가능한 효율적으로 쿼리하도록 데이터를 저장한다.
대부분의 데이터 세트에서 샤딩테이블과 파티셔닝 테이블은 서로 동일한 성능을 발휘한다.
하지만 매우 대용량 데이터세트의 경우 파티셔닝 테이블이 다음과 같은 이점을 제공한다.
- 샤딩테이블과 달리 파티셔닝 테이블에는 세트 당 하나의 메타데이터 세트만 존재한다.
따라서 샤딩테이블보다 더 작고 효율적이다. - 파티셔닝 테이블은 클러스터링을 지원한다.
빅쿼리의 쿼리 최적화 프로그램이 각 쿼리에서 스캔하는 파티션 수를 줄이기 위해 특정 필드를 지정할 수 있다.
빅쿼리에서 샤드테이블 생성 조건 및 방법.
- 동일한 데이터 세트에 존재해야 한다.
- 동일한 테이블 스키마를 가진다.
- 동일한 테이블명 prefix.
- 테이블명_YYYYMMDD 형식의 날짜 suffix.
다음 조건으로 테이블을 생성하면 빅쿼리에서 자동인식하여 샤드테이블로 구성함.
* 처음 생성시, 샤딩이 되지 않은 것처럼 각각 날짜로 생성되어 보이는 경우가 있는데, 새로고침 해주면 테이블 갯수만큼 괄호처리되어 샤드된 테이블을 확인할 수 있다.
ex)
* Business_(3)
- Business_20211201
- Business_20211202
- Business_20211203
'Data Analytics > Big Query' 카테고리의 다른 글
| [Big Query] 샤드 테이블 전체 삭제하는 방법. DROP shard tables (0) | 2024.03.21 |
|---|---|
| [Bigquery] Shard 테이블 날짜별 마이그레이션 (feat. 빅쿼리 절차적 언어_동적 SQL 만들기) (0) | 2024.03.14 |
| [Big Query] 빅쿼리 _ 컬럼 지향 스토리지란? Columnar Storage (1) | 2024.01.29 |
| [Big Query] 빅쿼리 SELECT 결과 데이터로 새 테이블 만들기. (1) | 2024.01.02 |
| [GA4-빅쿼리] 세션 재정의 해보기 (1) | 2023.01.12 |