일반적으로 전통적인 관계형 DBMS 의 스토리지 방식은 로우(ROW, 행) 지향 스토리지 방식으로 동작한다.
실무에서 빅쿼리를 접하게 되면서 빅쿼리가 빅데이터에 적합하게 만들어진 데이터베이스라는 건 알고 있었지만 여타 다른 SQL 문과 거의 동일한 방식의 쿼리를 사용할 수 있기 때문에 당연히 같은 방식으로 동작할거라는 편견을 나도 모르게 갖고 있던 터라 삽질을 하던 과정에서 빅쿼리는 통상적인 로우 지향이 아닌 컬럼 지향 스토리지 방식으로 동작한다는 사실을 알게되어 학습/기록한다.
컬럼 지향 스토리지 형식

- 빅쿼리는 완전 관리형 스토리지를 제공.
- 사용되는 빅쿼리 스토리지 크기는 자동 조절되며 과금은 사용한 만큼만 부과.
- 컬럼지향 스토리지에 담긴 데이터를 사용하여 대규모 데이터 분석 수행하도록 설계됨.
Postres나 MySQL과 같은 전통적인 관계형 데이터베이스에서는 데이터를 한 행씩 레코드 지향 스토리지에 저장한다.
레코드 지향에서는 발생하는 트랜젝션에 대해서 테이블 삽입/업데이트 등의 작업 시 하나의 레코드 단위로 읽고 쓰기 때문에 효율으로 동작한다. (OLTP 유리 )반대로 어떤 컬럼 내의 값들의 총합을 계산하는 것과 같은 집계 작업 수행시에는 전체 테이블의 내용을 메모리에 올려야 하는 부담이 생긴다.
빅쿼리는 이와 반대되는 개념의 컬럼 지향 스토리지는 사용하는데 여기서는 각각의 컬럼이 분리된 파일 블럭에 저장된다. (OLAP 유리) 집계연산이 필요한 경우 전체 테이블을 메모리에 올리는 대신 필요한 컬럼이 저장된 파일블럭들만 스토리지에서 읽어낼 수 있다.
스토리지 최적화.
내부적으로 빅쿼리는 데이터를 Capacitor 라는 컬럼 지향 형식으로 저장한다.
각각의 필드 또는 컬럼 값들이 분리되어 저장되면 파일을 읽어들일 때의 오버헤드는 실제로 읽고있는 필드의 갯수에 비례하게 된다. Capacitor 가 근사(approximation) 모델을 구축해서 데이터 타입이나 사용패턴과 같은 연관인자들을 고려해서 Row를 다시 섞거나 Column 을 인코딩 한다.
컬럼들이 인코딩 되는 동안에 빅쿼리는 데이터에 대한 다양한 통계 데이터를 수집한다. 통계 데이터는 따로 보관되었다가 향후 쿼리가 실행되는 동안 사용된다.

암호화와 내구성 관리.
빅쿼리의 영속계층은 구글의 분산파일시스템인 Colossus가 제공한다. 이곳에서 데이터는 자동으로 압축/ 암호화/ 복제/ 분산 된다. 구글 플라우드 플랫폼은 인가되지 않은 접근에 대해 여러단계의 방어체계를 갖추고 있다.
데이터를 100% 암호화하여 저장하는 것이 그 중 하나다.
Colossus는 삭제인코딩(Erasure encoding) 을 통해 데이터를 쪼개 서로다른 디스크에 고루 데이터 조각들이 저장될수 있도록 하여 내구성을 보장한다. 또한 데이터의 내구성/ 가용성 보장하기 위해 이 데이터들은 데이터셋을 생성한 권역(Resion)의 서로 다른 가용존에 복제된다.

즉, 데이터가 서로다른 체계와 네트워크를 가진 서로다른 건물에 보관된다는 의미다. 복수의 가용존에 데이터를 보관함으로써 재해 발생 시에도 안전한 데이터 복구가 가능하다.
쿼리 성능을 위한 스토리지 최적화.
빅쿼리는 스토리지 옵티마이저를 내장하고 있다.
옵티마이저는 파일을 주기적으로 다시 쓰면서 쿼리에 최적화된 형태가 되도록 데이터를 저장한다.
파일은 처음에는 쓰기에 최적화된 형태로 기록되다가 이후에 빠르게 조회할 수 있는 형태로 바뀐다.
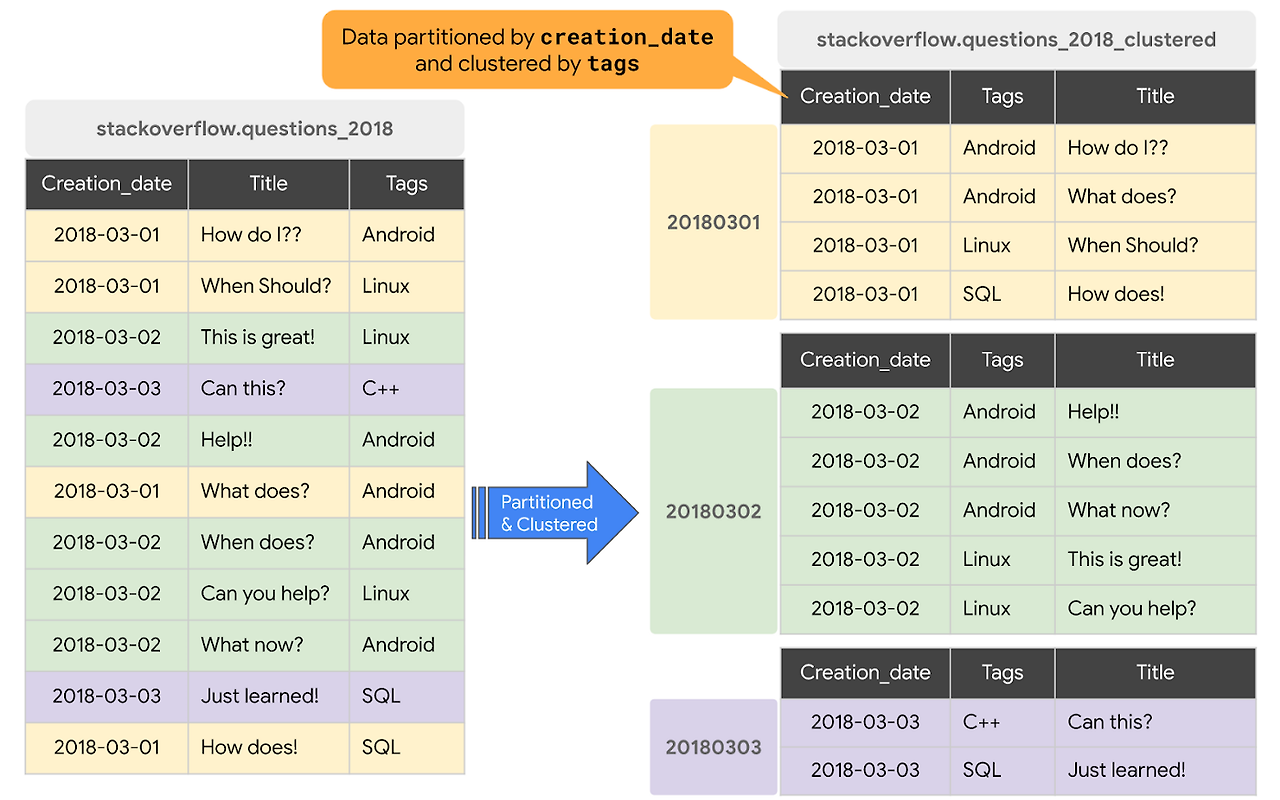
1. 파티셔닝 Partitioning
파티션된 테이블은 Partition이라 불리는 구역으로 나눠진 특별한 형태의 테이블이다.
빅쿼리는 파티셔닝을 통해 Worker(빅쿼리 Job을 수행하는 일종의 가상머신) 들이 디스크에서 읽어들이는 데이터의 양을 최소화 한다.
파티셔닝 컬럼에 대해 필터를 사용한 쿼리들은 데이터를 스캔하는 양을 극적으로 줄여 성능을 향상시키고, 스캔한 데이터량에 따른 과금체계 사용시 쿼리 비용절감 효과를 낼 수 있다.
파티션된 테이블에 쓰여진 새로운 데이터는 적절한 파티션으로 전달된다.

빅쿼리는 수집시간, 시간단위, 정수 범위 등을 기준으로 파티션된 테이블을 지원한다.
파티셔닝은 쿼리 성능을 최적화하기 위한 훌륭한 방법이다. 특히 대용량 테이블에서 분석을 위해 자주 데이터를 필터링 하며 줄여가는 경우에 유용하다.
적절한 파티션 키를 결정해야할 때는 항상 조직에 속한 사람들이 어떻게 테이블을 이용하는지 고려해야한다.
비용이 많이 드는 큰 테이블에서 파티션을 사용하는게 좋다. 반면 지나친 파티셔닝은 많은 메타데이터를 양산하고 이로 인해 속도를 느리게 만든다.
2. 클러스터링 Clustering
빅쿼리에서 테이블이 클러스터링 되면 데이터는 자동으로 하나 혹은 그 이상의 컬럼값을 기준으로 정렬된다.
높은 카디널리티(하나의 컬럼이 가지는 고유한 값의 수)와 날짜시간 형식이 아닌 컬럼들이 클러스터링에 적합하다.
특히 다음과 같은 상황에서 클러스터링은 개선된 쿼리 성능을 보여준다.
- 클러스터 컬럼이 WHERE 조건에 포함될 때: 빅쿼리는 정렬된 블럭을 사용하여 불필요한 데이터 스캔을 제거한다. WHERE절의 필터순서가 중요하게 작용하므로 클러스터링을 사용하는 필터를 먼저 사용한다.
- 클러스터 컬럼의 값들을 기반으로 데이터를 집계하는 경우: 정렬된 블럭들은 유사한 값들을 가진 행들과 같이 위치하기 때문에 성능이 개선된다.
- JOIN 키가 테이블 클러스터링을 위해 사용되는 JOIN 연산: 적은 데이터만 스캔된다. 어떤 쿼리에서는 클러스터링이 파티셔닝 대비 큰 성능 개선을 보여준다.
참고자료)
https://cloud.google.com/blog/topics/developers-practitioners/bigquery-admin-reference-guide-storage?hl=enhttps://velog.io/@jaytiger/BigQuery-Architecture-Storage-Internals
'Data Analytics > Big Query' 카테고리의 다른 글
| [Bigquery] Shard 테이블 날짜별 마이그레이션 (feat. 빅쿼리 절차적 언어_동적 SQL 만들기) (0) | 2024.03.14 |
|---|---|
| [Big Query] 테이블 샤딩이란? Table Sharding. (0) | 2024.02.26 |
| [Big Query] 빅쿼리 SELECT 결과 데이터로 새 테이블 만들기. (1) | 2024.01.02 |
| [GA4-빅쿼리] 세션 재정의 해보기 (1) | 2023.01.12 |
| [빅쿼리] ARRAY / STRUCT / UNNEST. 정체가 무엇이냐?? (2) | 2023.01.04 |